双端队列的两种实现方式
零,前言
CS61B第三周的Project1A:
内容是实现Deque这种双向链表数据结构,底层的实现方式分别是基于内存不连续的链表和内存连续的数组
一,基于链表的Deque:LinkedListDeque
实现要求
public void addFirst(T item): Adds an item of typeTto the front of the deque.public void addLast(T item): Adds an item of typeTto the back of the deque.public boolean isEmpty(): Returns true if deque is empty, false otherwise.public int size(): Returns the number of items in the deque.public void printDeque(): Prints the items in the deque from first to last, separated by a space. Once all the items have been printed, print out a new line.public T removeFirst(): Removes and returns the item at the front of the deque. If no such item exists, returns null.public T removeLast(): Removes and returns the item at the back of the deque. If no such item exists, returns null.public T get(int index): Gets the item at the given index, where 0 is the front, 1 is the next item, and so forth. If no such item exists, returns null. Must not alter the deque!public LinkedListDeque(): Creates an empty linked list deque.public LinkedListDeque(LinkedListDeque other): Creates a deep copy ofother. Creating a deep copy means that you create an entirely newLinkedListDeque, with the exact same items asother. However, they should be different objects, i.e. if you changeother, the newLinkedListDequeyou created should not change as well. (Edit 2/6/2018: A walkthrough that provides a solution for this copy constructor is available at https://www.youtube.com/watch?v=JNroRiEG7U4)public T getRecursive(int index): Same as get, but uses recursion.
思想和注意要点
第一种基于链表的实现,因为是双向链表,而且为了避免一些corner case,所以添加了一个sentinelnote ,就是一个哨兵节点或者叫做哑节点。这个节点自身不存有任何的信息,只有一个next和prev分别指向下一个节点(一般是头节点)和前一个节点(一般是尾节点)。如下图所示
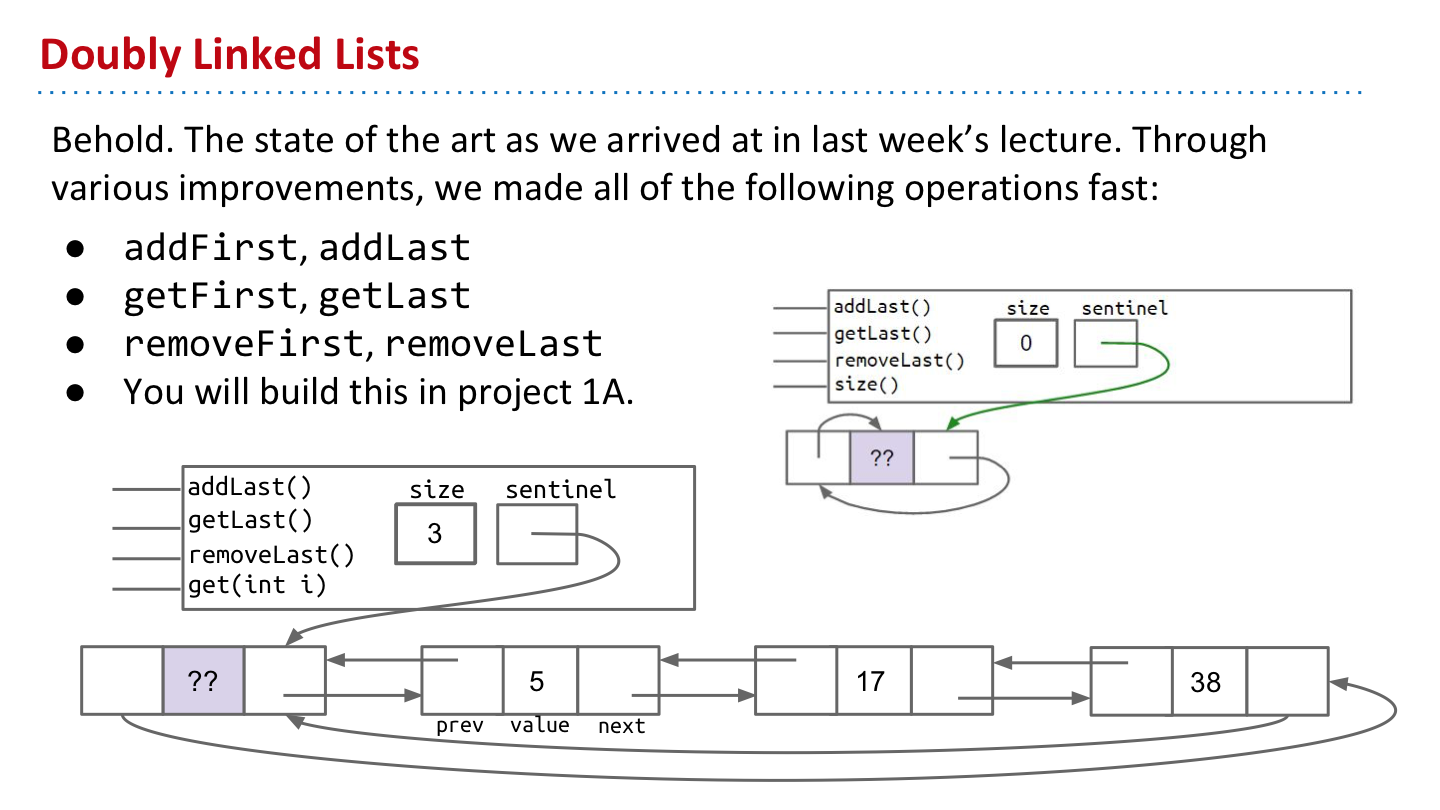
总的来说实现起来没有多大的困难(当然我好久没写代码了,写了好久555
需要注意的是添加删除节点时候的一些关系,比方说下面这个向头部添加一个节点
public void addFirst(T item)
{
Node rest = sentinelNode.next;
Node newFirstNode = new Node(sentinelNode, item, rest);
sentinelNode.next = newFirstNode;
if(rest != null) {
rest.prev = sentinelNode.next;
}
else {
//只有一个节点的时候,新创建的节点的下一个和上一个节点都是senti
newFirstNode.next = sentinelNode;
sentinelNode.prev = newFirstNode;
}
size++;
}事实上,如果sentinelNode一开始size=0的时候prev和next都指向自身,代码可以简化,不需要有sentinelNode.next判断为null的特殊情况。
public void addFirst(T item) {
Node node = new Node(sentinel, item, sentinel.next);
sentinel.next.prev = node;
sentinel.next = node;
size += 1;
}二,基于数组的Deque:ArrayDeque
同样是实现双向链表,只是底层的数据结构是数组,这个难度我认为大一点。由于实现的函数与上面一样,都有在头部和尾部添加节点以及删除节点的行为。所以我们把整个数组看成是环状数组。靠两个下标headIndex和tailIndex来记录当前头部位置和尾部位置。

头部和尾部指针/下标/索引
一个难点是当往头部或者尾部插入节点时,headIndex和tailIndex应该怎么移动的问题。一开始我设想了很多种corner case,但实际上只要加一再对数组容量取余或者减一取余就可以了。其实只有两种情况,一种是head小于tail,另一种则是head大于tail。
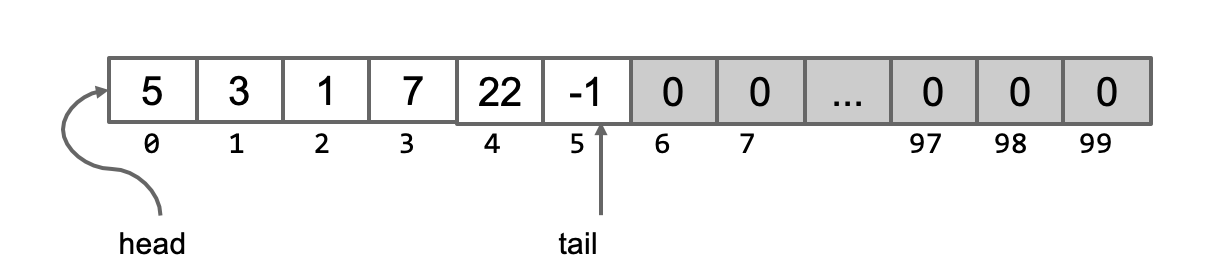
比方说一开始只往尾部添加,不断地调用addLast(),那么就如下所示。head在tail左侧
但也有可能如下所示,先addFirst然后再addLast
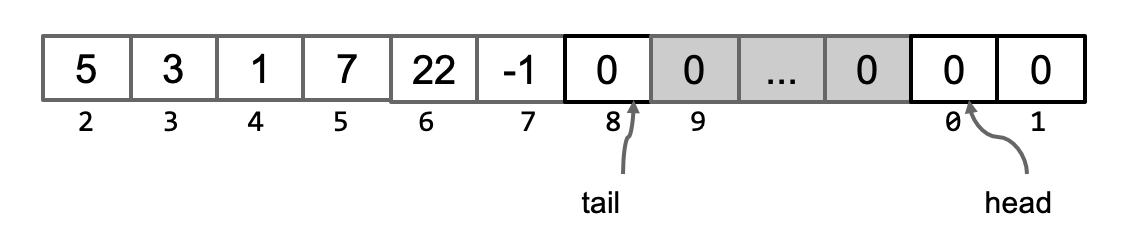
总之,只有这两种情况。如果我们把整个数组看成一个收尾连接的圆环(实际上我们实现的效果就是这样的),那么head的增长方向和tail的增长方向都是不变且相反的。如上图所示,head一直向“左”走,而tail一直向“右”走。只不过当他们各自抵达数组的真实头尾时会从另一边开始继续走。
因此代码如下(先不管扩容部分)
public void addFirst(T item)
{
if(size + 1 > capacity)
{
//扩容一倍
scale(FACTOR);
}
if (size != 0) {
headIndex = (headIndex + capacity - 1) % capacity;
}
items[headIndex] = item;
size++;
} public void addLast(T item)
{
if(size + 1 > capacity)
{
//扩容一倍
scale(FACTOR);
}
if(size != 0) {
tailIndex = (tailIndex + capacity + 1) % capacity;
}
//当tailIndex和headIndex重合时,就是0个元素
items[tailIndex] = item;
size++;
}扩容和缩容
由于底层的数据结构是数组,因此我们一开始分配的空间是一定的。如果我们持续不断的添加元素,数组就势必要扩容。而删除元素到一定程度,为了节省空间则需要缩容。扩容感觉很自然,毕竟装不下了就要扩容,天经地义。那缩容的必要性呢?
考虑一种情况,先插入1万个元素,然后再删除9999个元素,只剩下一个元素。但是现在的数组却因为之前的扩容而占据了1万个元素的空间。
因此我们需要缩容,并且指定一个标准,比方说当前元素个数占据总容量的四分之一以下的时候,缩容一半。代码如下
public void scale(int multiple)
{
if(multiple < 1)
return;
T[] scaledItems = (T[])new Object[capacity * multiple];
//拷贝的时候应该分为两种情况
//(1)head在左侧,tail在右侧,这就是正常顺序
//(2)tail在左侧,head在右侧,这是一端超过末尾了
if(headIndex < tailIndex) {
System.arraycopy(items, headIndex, scaledItems, 0, tailIndex - headIndex + 1);
}
else {
//复制从第headIndex元素到线型数组最后一个下标所在的元素
//复制从第0个下标对应元素到tailIndex(应该是headIndex - 1)的所有元素
System.arraycopy(items, headIndex, scaledItems, 0, capacity - headIndex);
System.arraycopy(items, 0, scaledItems, capacity - headIndex, tailIndex + 1);
}
items = scaledItems;
capacity *= multiple;
criticalValue = capacity / 4; //只有在每次扩容和缩容时计算一次临界值,这样每次只要和临界值比大小就可以了
//重置头尾节点
headIndex = 0;
tailIndex = size - 1;
}public void descale(int shrink)
{
if(shrink < 1)
return;
//缩容通常是2倍缩小
T[] scaledItems = (T[])new Object[capacity / shrink];
if(headIndex < tailIndex) {
// 无论缩容还是扩容,都不会出现headIndex和tailIndex重合的情况(这两者只有size = 0时候才会重合)
System.arraycopy(items, headIndex, scaledItems, 0, tailIndex - headIndex + 1);
}
else {
System.arraycopy(items, headIndex, scaledItems, 0, capacity - headIndex);
System.arraycopy(items, 0, scaledItems, capacity - headIndex, tailIndex + 1);
}
items = scaledItems;
capacity /= shrink;
criticalValue = capacity / 4; //只有在每次扩容和缩容时计算一次临界值,这样每次只要和临界值比大小就可以了
//重置头尾节点
headIndex = 0;
tailIndex = size - 1;
}三,总结
这次Project算是重新让我温故了一下链表,以及好久没写过的Java(我甚至好久没写代码了。。。)。深感写代码的人还是需要熟能生巧,我大一的时候甚至都可能比现在写到更快更熟练。总之接下来就是一个字 “练”。
四,参考资料与相关链接
【1】实现代码
【3】Project1A
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!